During the last 12 months I have been busy working on projects and lost my way a little bit on writing and sharing my experiences with the community. However on a positive note I learned a lot of new things during that period and now I’ve got some great content planned and waiting to be shared with you all.
Some of those learnings were around working with large CDS datasets in Microsoft Power Automate Flows and Azure Logic Apps. Here are some of those easy to learn tips, tricks, guidelines and limitations that will help you for sure.
Connecting to a Common Data Service (CDS) environment
There are two main connectors you can use. “Common Data Service” connector and “Common Data Service (current environment)” connector. Let’s look at few points to consider when selecting a connector for your workflow.
| Common Data Service connector | Common Data Service (current environment) connector |
|---|---|
| Available for both Power Automate Flows and Logic Apps. | CDS (current environment) is only available in Microsoft Power Automate and is not available in Microsoft Logic Apps. This is due to flows being hosted within the environment and has the ability to automatically detect the current environment. Logic Apps are hosted externally in azure resource groups and hence cannot use the CDS (current environment) connector. |
| Allows you to connect to different CDS environments. | Always connects to the environment the flow is hosted on. |
There are differences in triggers and actions of these connectors. I found the below posts very helpful in learning them.
CDS vs CDS: What Connector should I use in Power Automate? – Sara Lagerquist
Common Data Service (Current Environment) Cheat Sheet – Dani Kahil
I believe these connectors are there to serve different purposes. However it would be great if Microsoft standardised them and supported the same set of actions and triggers. This way there will be no difference in implementation and capability.
Querying Data
Both CDS and CDS (current environment) connectors support “List Records” action to retrieve data from a CDS environment.
- CDS and CDS (current environment) connectors both supports OData queries and filtering.
- Only CDS (current environment) supports FetchXML queries.
- When using OData queries there is a limit of 100,000 records as per the connector limitations. To use the maximum limit you will need to use pagination threshold property under the settings area of “List Records” action.

- Using FetchXML queries will limit the maximum number of records returned to 5000 records regardless of the pagination threshold set.
- To get around this issue you can use FetchXML Builder XrmToolBox plugin to convert your FetchXML queries to OData queries.
- Default limits of “List Records” action
- When using CDS (current environment) connector “List Records” action, if the “Top Count” parameter is not set the max returned record count defaults to 5000. It is important to set the “Top Count” parameter and enable pagination with a threshold if you are expecting more than 5000 records returned. (When using CDS connector the max returned record count defaults to 512.)
- The connector action says the top count default = all but this is misleading, when tested it only returned a maximum of 5000 and 512 as mentioned above when NO top count parameter is set.

- Top count and pagination threshold parameters have limitations when using FetchXML queries. Even if the parameter is set to a value greater than 5000 when a FetchXML query is used the maximum number of records returned will still be 5000 records.
- Pagination work in 512 records per page. This means the number of records returned may exceed the actual threshold (up to 511 records more).
- i.e. if you set the pagination threshold to 60,000 you may get up to 60,416 records returned. This is because the 60,416 is equal to 118 pages of data (512 records per page).
- To get around this you may want to set “Top Count” parameter together with the paging threshold.
- When using FetchXML, “Select Query” and “Expand Query” parameters are ignored as both of them can be defined in the FetchXML query it self as select attributes and linked entities.

If you are intending to use OData queries and expand query parameters, then here is a great post by Lin Zaw Win on how to do it: [Power Automate] List Records – Use Expand Query to Retrieve Related Data in flow - CDS (current environment) connector’s “List Records” action has a maximum buffer size configured. So you should try and limit the number of fields returned to reduce the byte count returned. This applies to MS Power Automate.
Http request failed as there is an error: 'Cannot write more bytes to the buffer than the configured maximum buffer size: 104857600.'.
“List Records” action of CDS connector in LogicApps has a larger buffer limit of ‘209715200’ (which is 2x of what is in flow)The action 'List_records' has an aggregated page results size of more than '211157749' bytes. This exceeded the maximum size '209715200' bytes allowed.
- CDS connector supports “Aggregation Transformation” (which is not available in the current environment connector). Even though the OData retrieval is possible for up to 100,000 records, aggregate functions only supports up to 50,000 records.
- If you try to use an aggregate function on a larger data set than 50,000 you would get an “AggregateQueryRecordLimit exceeded” error.
- You could use a filter to reduce the record count for your aggregation to get around this.


- Also when you define you queries always try to add an order by clause/rule, so you pick up the most important records first. (This will also help in a scenario where your job run fails and when it runs again it will pick up the records in the order given.)
Data Processing
Once the query is run and the results are returned you will have the data set ready to be processed.
- Looping through records can be done using:
- “Apply to each” control in Power Automate Flows
- “For each” control in Logic Apps
- Both above looping controls have concurrency controls to improve the performance of processing records.
- However if you are using variables within your loops then you should AVOID parallel runs. This is because the same variable will be referenced within multiple parallel runs/threads at the same time and may not give you the desired output.
Default in Power Automate flows is to run sequentially. But in Logic Apps the default is to run in parallel.

- Both Power Automate and Logic Apps does not allow variables to be initiated within loop controls. Since variables are defined outside of the loop and then used within the loops, multiple concurrent runs will not work well with variables.
- To force your loops to run one record at a time you need to enable concurrency controls and set the degree of parallelism to 1.

- Please note that by using variables within your loops you are restricting the usage of parallel runs and this will impact the performance of the workflow.
- However if you are using variables within your loops then you should AVOID parallel runs. This is because the same variable will be referenced within multiple parallel runs/threads at the same time and may not give you the desired output.
Error Handling
When you process large data sets you should track and trace the result of each record processed and action it in a safe manner. If some records fail during processing, you should catch the error safely and avoid failure/cancellation of the whole job.
- Using scope controls to handle errors
- Both Power Automate and Logic Apps support scope controls and these can be used as try and catch blocks for error handling.
- You can use try catch blocks within your loop so you can handle errors of each record separately.

- When configuring the catch block you need to set the catch block to only run if try block is failed or timed out.
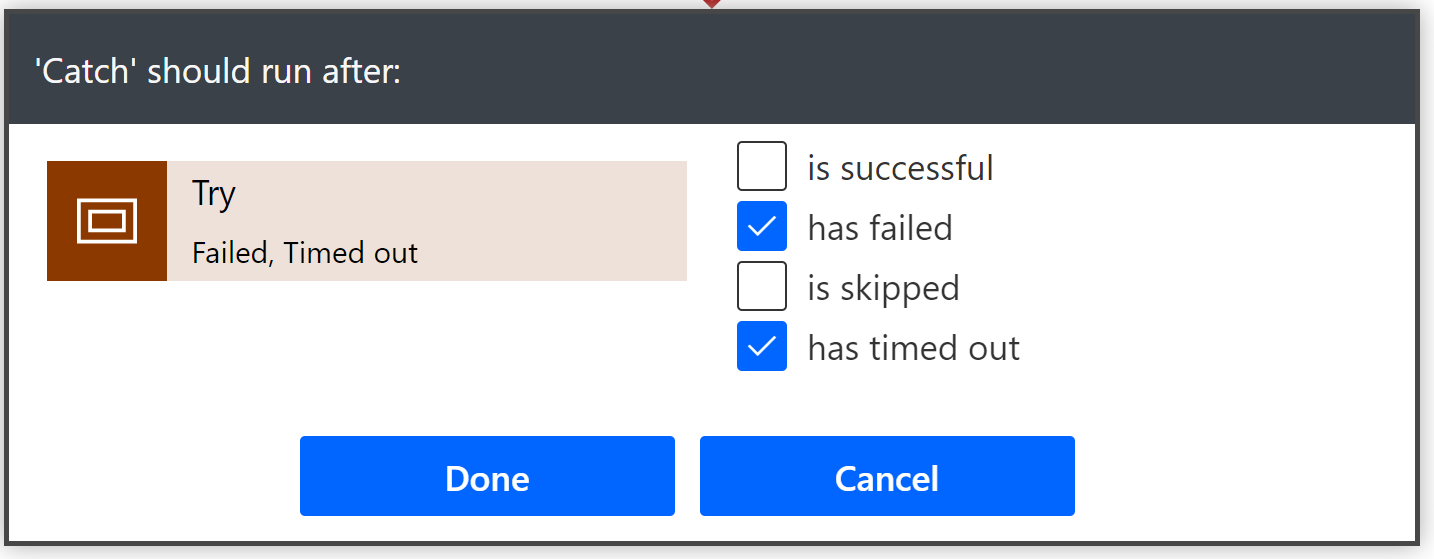
- If you want to perform multiple tasks as one transactional event and rollback the changes if one of those sub tasks fails, then you should call a bound/unbound action registered in your CDS environment. If this action is registered to run synchronously then a failure within the action will revert the changes back.

Scheduling
If your Flow/Logic App is triggered based on a recurring schedule and if your workflow runs for a long time, there is a chance that the Flow/Logic App may trigger again before the current run ends. This may result in same records being processed twice. To prevent this from occurring you need to follow a singleton pattern/approach. The easiest way to do this is by setting the concurrency setting on the recurrence trigger to 1. This will ensure only one instance of the workflow is run at a given time.
It’s always a good idea to limit your data set to a manageable size and share the load over multiple runs if possible. This will reduce the risk of long running processes.

Reblogged this on Nishant Rana's Weblog.
LikeLike
Reblogged this on Ricky Safford Development Repository and commented:
Great insight into working with large datasets with PowerAutomate/Flow in CDS/Dataverse!
LikeLike
Thanks for this wonderful post Thanura. Is there any we can retrieve more than 5000 records using Fetch XML + List records ?
LikeLike
Converting fetchXML to OData queries is the first option I try. But there are limitations to what you can and can’t do with OData expressions (Especially on linked entities). Other option is to design the flow to retrieve records grouped by an attribute and then process the data sets after.
In some scenarios you can also check whether there are more records to be processed at the end of the flow run and then re-initiate another flow run (or by using a while loop within the same flow).
LikeLiked by 1 person
Yes, I’ve done something similar before where I had nearly a million records to process. I used a schedule trigger (disabling the concurrency so that only one at a time will run) and so it will repeat for each data set. After the flow had finished, the next time it queried the data, the records previously processed would not be returned because they did not match the query conditions, so it was safe for it to run over and over and over.
I’ve also found that large amounts of rows returned seemed to slow the flow down. I found that top 2500 finished processing in less than half the time that top 5000 took. Sometimes less is more 🙂
LikeLiked by 1 person